I am not often puzzled when looking at TSQL syntax, but this one time I could not figure out the syntax. Syntax looked similar to the example below.
SELECT t.*
, s.*
FROM Teacher AS t
LEFT OUTER JOIN dbo.Student AS s
JOIN dbo.Grades AS gr
ON s.ID = gr.StudentID
AND gr.GradeLetter = 'A'
ON s.TeacherID = t.ID
My first gut reaction was that this code is broken and would not run. To my amazement code ran just fine. Now came the hard part, which was to figure out what the code was doing because I have never seen this syntax before. Since I did not understand what I was looking at I could not BING "weird join syntax" to get an answer. As a developer, I learned long time ago to break down code into smallest possible chunks to get the answer.
After I have figured out the relationship between tables, I was able to understand what query was doing. To be able to read query better it can be rewritten in the following way.
SELECT t.*
, s.*
FROM Teacher AS t
LEFT OUTER JOIN
(
SELECT s.*
, gr.*
FROM dbo.students AS s
JOIN dbo.Grades AS gr
ON s.ID = gr.StudentID
AND gr.GradeLetter = 'A'
) AS s
ON s.TeacherID = t.ID
This code is much easier to read and to understand. Students filtered by Grades and we are only interested in Students who have "A" grade. Therefore we get all records from Teacher table but only get Students who have good grades. If we would try to rewrite the query in the following matter, we would only get Teachers that have Students with perfect grades as we specified inner join; therefore, it takes precedence over the left outer join.
SELECT t.*
, s.*
FROM Teacher AS t
LEFT OUTER JOIN dbo.Student AS s
ON s.TeacherID = t.ID
JOIN dbo.Grades AS gr
ON s.ID = gr.StudentID
AND gr.GradeLetter = 'A'
Now that I knew what code was doing I wanted to know performance because I do not care how the code looks as long as it does not perform fast it is useless. The execution plans of the two queries are almost identical with the only difference being that when I rewrote the original query as sub-query, I got additional operation added to the plan. Physical joins were identical and execution time was almost exact.
I could not believe I learned something new after writing T-SQL for many years. All of the sudden I got another tool in my toolbelt to write better code. Now if I ever need to filter tables that should not effect result I can write with this new syntax. To be honest, I have not taken this to the extreme to see how many JOIN operations I can nest before it becomes unreadable. However, I am sure it would not take many before someone else could not figure out what was going on and would have to break it down piece by piece to see it clear.
Just imagine having to support code that looks like example 1 below instead of example 2. Even though the code in the following case produces same execution plan, it becomes hard to read and therefore hard to maintain, and if you have junior developers who are not strong in SQL, they are more likely to make mistakes.
--Example 1:
SELECT t.FullName AS TeacherName
, s.FullName AS StudentName
, gr.Class
FROM dbo.Teacher AS t
JOIN dbo.Student AS s
JOIN dbo.Grades AS gr
JOIN dbo.Class AS c
JOIN dbo.Room AS r
ON c.ID = gr.ClassID
ON r.ClassID = c.ID
ON s.ID = gr.StudentID
ON s.TeacherID = t.ID
--Example 2:
SELECT t.FullName AS TeacherName
, s.FullName AS StudentName
, gr.Class
FROM dbo.Teacher AS t
JOIN dbo.Student AS s
ON t.ID = s.TeacherID
JOIN dbo.Grades AS gr
ON s.ID = gr.StudentID
JOIN dbo.Class AS c
ON c.ID = r.ClassID
JOIN dbo.Room AS r
ON c.ID = gr.ClassID
P.S. I still don't know if this JOIN syntax has special name, but at least I now know what it does.
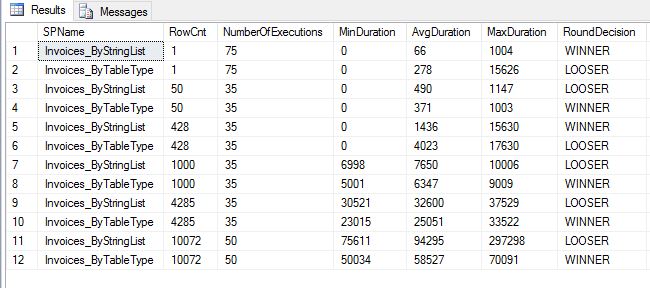
I don't think I have tested for every scenario possible, but it is better than only a single test. With that being said, I'm a little surprised at the result. I thought that User Defined Table Type would win in every scenario but it is clear that in some cases STRING_SPLIT() function is actually faster. Just like most other things in SQL Server the answer is: It Depends!
In the case of STRING_SPLIT() function Engineers at Microsoft did amazing job optimizing it over other custom solutions that people had to resort to in the past. Of course there are limitations with it, that need to be acknowledged and taken into consideration when designing a solution. In my opinion this could be quick go to solution that is great for initial testing but needs to be heavily tested when it comes to final solution for production environment.
Just like I mentioned in previous post, estimated row count always shows 50 rows and value returned from the function is a string and needs to be converted to target type. This did not prove to be large issue in my testing but in complex execution plans it could throw query optimizer into wrong plan when getting data from other tables which could cause major slow downs.
In my test scenarios outlined below, User Defined Table Type Won 4 out of 6 times. I'm sure I could have setup other scenarios where it would lose every time but in this case it won. Leave comments if you want to see full source code or want me to run any other scenarios. Thanks for reading!
SELECT a.*
, CASE WHEN ( MAX(a.AvgDuration) OVER ( PARTITION BY RowCnt ) ) = AvgDuration
THEN 'LOOSER' ELSE 'WINNER' END AS RoundDecision
, ROW_NUMBER() OVER ( ORDER BY RowCnt, SPName ) AS RowNumber
FROM (
SELECT SPName
, RowCnt
, COUNT(*) AS NumberOfExecutions
, MIN(Duration) AS MinDuration
, AVG(Duration) AS AvgDuration
, MAX(duration) AS MaxDuration
FROM dbo.SPExecutionTime
GROUP BY SPName
, RowCnt
) a
ORDER BY RowNumber
During SQL Saturday Indianapolis I heard about new function introduced in SQL Server 2016 STRING_SPLIT(). Presenter showed few examples of how to use it and mentioned that it is faster than other implementations of what people had to previously done. This got me excited and I wanted to see how it compares to User Defined Table Types which has always been my go to replacement for string splitting.
This post is not about comparing new function to other function, Aaron Bertrand already did a great post comparing it to other solutions. IT can be found here -> Performance Surprises and Assumptions : STRING_SPLIT(). What I wanted to do is compare it to User Defined Table Types because it always been faster (at least this is what I think about it).
Now unto test scenario. First time I had to replace string splitting function with User Defined Table Typed Parameter was when I had to rewrite stored procedure that accepted a list of 5000 items inside varchar(max) parameter. With that in mind I decided to test new function the same way. Pass a huge string, split it inside stored procedure and return result set back to .NET application. For this test I created two stored procedures running against Wide World Importers Test Database.
/*
==============================================================================================================================
Author: Vlady Oselsky
Create date: 08/15/2016
Description: Testing String Split Function
==============================================================================================================================
*/
CREATE PROCEDURE [dbo].[Invoices_ByTableType]
(
@List IdList READONLY
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StartTime datetime2 = SYSDATETIME();
DECLARE @RwCnt int;
select iv.SalespersonPersonID
,iv.InvoiceDate
,iv.DeliveryInstructions
from WideWorldImporters.Sales.Invoices as iv
join @List as l
on iv.InvoiceID = l.ID
order by 1
SET @RwCnt = @@ROWCOUNT
DECLARE @EndTime Datetime2 = Sysdatetime();
INSERT INTO SPExecutionTime (SPName,RowCnt, Duration)
VALUES(OBJECT_NAME(@@PROCID),@rwCnt, DATEDIFF(MICROSECOND, @StartTime, @EndTime))
END
GO
/*
==============================================================================================================================
Author: Vlady Oselsky
Create date: 08/15/2016
Description: Testing String Split Function
==============================================================================================================================
*/
CREATE PROCEDURE [dbo].[Invoices_ByStringList]
(
@List VARCHAR(MAX)
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StartTime datetime2 = SYSDATETIME();
DECLARE @RwCnt int;
select iv.SalespersonPersonID
,iv.InvoiceDate
,iv.DeliveryInstructions
from WideWorldImporters.Sales.Invoices as iv
join string_split(@List, ',') as l
on iv.InvoiceID = l.value
order by 1
SET @RwCnt = @@ROWCOUNT
DECLARE @EndTime Datetime2 = Sysdatetime();
INSERT INTO SPExecutionTime (SPName,RowCnt, Duration)
VALUES(OBJECT_NAME(@@PROCID),@rwCnt, DATEDIFF(MICROSECOND, @StartTime, @EndTime))
END
Below is the script for user defined table type and table to store results on SQL Side. I done this in order to compare SQL duration to total duration on .NET side
CREATE TYPE [dbo].[IdList] AS TABLE( [ID] [int] NULL )
GO
CREATE TABLE dbo.SPExecutionTime
(
ID INT IDENTITY(1,1) PRIMARY KEY
,SPName sysname
,RowCnt INT
,Duration INT
)
GO
Now onto .NET C# code. To be fair I wanted to pass entire value on .NET side instead of trying to build it just before calling stored procedure. Below is the code for calling TableType stored procedure, as you can see instead of having VarChar type, I have Structured type which accepts IEnumerable variable. In my case I'm passing DataTable.
stopwatch.Start(); //Time starts here
DataTable table = new DataTable();
using (var con = new SqlConnection(connectionString))
{
con.Open();
var cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "Invoices_ByTableType";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("@List", SqlDbType.Structured, -1).Value = hugeListTable;
using (var da = new SqlDataAdapter(cmd))
{
da.Fill(table);
}
}
dataGridView2.DataSource = table;
stopwatch.Stop(); //Time ends Here
Next comes a call to stored procedure with VARCHAR(MAX).
stopwatch.Start();
DataTable table = new DataTable();
using (var con = new SqlConnection(connectionString))
{
con.Open();
var cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "Invoices_ByStringList";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("@List", SqlDbType.VarChar, -1).Value = hugeListString;
using (var da = new SqlDataAdapter(cmd))
{
da.Fill(table);
}
}
dataGridView1.DataSource = table;
stopwatch.Stop();
On front end I setup simple interface with two buttons and a way to aggregate data together. After running each stored procedure 50 times. I came up with the following result.
Conclusion: Round 1 goes to User Defined Table Type. One thing I noticed when looking at execution plans. I saw that string_split() function always estimates 50 rows, whereas when calling with user defined table type estimated row count matches actual. Additionally there is implicit conversion because string returned from split function and I'm joining it to integer column. Next I want to make few other adjustment to stored procedures and front end to try to call it with different number of rows to see how it changes the outcome.
I have another opportunity to share my T-SQL knowledge. This time, it will be in Birmingham, AL at dev-data DAY on August 20. This will be a free conference with SQL, .NET, Powershell/Azure and Professional Development sessions. I'm happy to present "Crash Course on Better SQL Development" session which includes elements of T-SQL coding, error handling, a look at execution plans and finally exploring some capabilities of SSDT (SQL Server Data Tools).
This year it will by my 5th time speaking at local events. Each new event brings a new perspective into local user group communities and different knowledge that technology professionals bring to the market. For me, speaking became a way to share and at the same polish my own knowledge. Depending on experiences and knowledge of each group, there are different questions which lead a session on a slightly different path. Presenting same content takes different shape with every new group of people.
For me, one of the biggest challenges that I had to overcome in order to become a speaker was to realize that it is perfectly fine to admit that I don't know an answer to every question. Whenever a difficult question is asked, I do my best to answer based on my knowledge at that time and take a time to research it after the fact to make myself prepared for it next time. I'm not an expert in any given field and will never claim to be one. I like to be Jack of all trades. Being diverse in my knowledge helps me to approach problems from a different perspective and think of solutions from different angles.
Today was the proof that I have a lot to learn about DBA tasks. I took on a somewhat simple task of renaming a database that turned into a 30-minute ordeal. Hopefully, this post will save you some time by avoiding issues that I ran into. Below I outlined one of the possible ways of getting this task done. Please note that this can result in outage and should not be done in production (live) environment, unless you are confident in what you are doing and it is done during a maintenance window.
Step 1
Before we can rename DB we need to identify Logical and Physical file names. I recommend copying result to notepad or somewhere else as it will be easier to paste it into later queries. To get names we can query system table in master DB. In my scenario, my Database Name is "VladTesting"
USE [master]
GO
/* Important to get logical and physical file names */
SELECT name AS [Logical Name]
,physical_name AS [DB File Path]
,type_desc AS [File Type]
,state_desc AS [State]
FROM sys.master_files
WHERE database_id = DB_ID(N'VladTesting')
GO
Logical Name
DB File Path
File Type
State
VladTesting
C:\SQL Server Data Files\MSSQL11\Data\VladTesting.mdf
ROWS
ONLINE
VladTesting_log
C:\SQL Server Data Files\MSSQL11\Log\VladTesting_log.ldf
LOG
ONLINE
Step 2
Now we are ready to start the process. Before logic names can be renamed we need to have exclusive rights to DB.
ALTER DATABASE VladTesting
SET SINGLE_USER WITH ROLLBACK IMMEDIATE
Step 3
Now when we execute the following statement it will rename logical file names.
ALTER DATABASE [VladTesting] MODIFY FILE
(NAME=N'VladTesting', NEWNAME=N'VladsAwesomeDB')
GO
ALTER DATABASE [VladTesting] MODIFY FILE
(NAME=N'VladTesting_log', NEWNAME=N'VladsAwesomeDB')
GO
Step 4
At this point we have several options, the following is one of the easiest. We need to DETACH database, rename files and than attach it with new name later.
Another option is to take DB Offline and rename files and later rename DB.
EXEC master.dbo.sp_detach_db @dbname = N'VladTesting'
GO
Step 5
Now to rename the files it can be done from SSMS with TSQL or directly on file system. NOTE: When I ran the following command it messed up file permissions, this should be used with caution. It is safer to ask System Admins or someone else with proper file system permissions to rename files directly on file system, then it is possible to shift the blame if something goes wrong (just kidding).
Most of the time XP_CMDSHELL is not enable as it is considered dangerous, to enable it, just run the following code.
EXEC sp_configure 'show advanced options' ,1;
GO
RECONFIGURE;
GO
EXEC sp_configure 'xp_cmdshell' ,1;
GO
RECONFIGURE;
GO
Step 6
Now to actually rename the files, we simply provide old file name with path and new filename to the XP_CMDSHELL command.
In order to execute rename command we first need to enable XP_CMDSHELL if it is not already enabled.
EXEC xp_cmdshell 'RENAME "C:\SQL Server Data Files\MSSQL11\Data\VladTesting.mdf", "NewDatabaseName.mdf"'
GO
EXEC xp_cmdshell 'RENAME "C:\SQL Server Data Files\MSSQL11\Log\VladTesting_log.ldf", "NewDatabaseName_log.ldf"'
GO
Step 7
Now for the last step. We attach DB with new name and new physical file names that we just renamed.
CREATE DATABASE VladsAwesomeDB ON
( FILENAME = N'C:\SQL Server Data Files\MSSQL11\Data\VladsAwesomeDB.mdf' ),
( FILENAME = N'C:\SQL Server Data Files\MSSQL11\Log\VladsAwesomeDB_log.ldf' ) FOR ATTACH
GO
ALTER DATABASE VladsAwesomeDB SET MULTI_USER
GO
Step 8 - Housekeeping
Since xp_cmdshell considered dangerous it is best to disable before we forget that it had to be enabled. First command will disable xp_cmdshell and second command will hide advanced options.
EXEC sp_configure 'xp_cmdshell' ,0;
GO
RECONFIGURE;
GO
EXEC sp_configure 'show advanced options' ,0;
GO
RECONFIGURE;
GO
So now you know how to rename database. Usually this should only be done when there is specific business reason to do so. If command sp_renamedb or ALTER DATABASE Modify Name is used, it does not rename physical or logical files which can cause issues later when someone tries to create new database with same name as last one or someone does restore of backup without changing options.
This topic takes me back to my first SQL Server database class I had in college. Back then it was extremely difficult subject for me. Partly because I have worked very little with databases and secondary, because of the way it was presented. Taking all that into account let's try to attack it in most basic manner. SQL JOIN in its basic form is just a way to connect two tables together. There are several types of JOINs that can be defined: LEFT, RIGHT, FULL, INNER, CROSS. There are time and place for each one, but most of the time I can get away with using only LEFT and INNER.
Its is great to talk about JOINs, but I'm sure that there are other people who like me don't learn but hearing, they learn by seeing and trying it them self. To do that, we need to create two basic tables and populate it with some data.
First, let us create two tables to store data for our tests. Since the concept of student and teacher is most easily understood, I'm creating Teacher table and Student table with a key to link back to Teacher Table.
Now that we got some data loaded into tables let the JOINing commence. First will look at 'INNER' JOIN
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
INNER JOIN Student s
ON s.TeacherID = t.ID
INNER JOIN throws out all records that do not match. In our case Teacher "Sonnie Davin" and Student "Dion Hayden" do not appear in result because there was no way to connect those records.
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Roy Chad
Milburn Brett
Dudley Goddard
Clinton Schuylerr
Dudley Goddard
Norbert Kemp
Raphael Philander
Meriwether Kennedy
Raphael Philander
Braith Cornelius
LEFT OUTER JOIN, returns all records from main table and attempts to match records from secondary table.
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
LEFT OUTER JOIN Student s
ON s.TeacherID = t.ID
As seen in this result list, Teacher "Sonnie Davin" appears in the list but does not have any student records associated. LEFT JOIN is most usefull when ever you not sure if you all records from main table are matched in secondary table. Almost every time I write query I use LEFT JOIN the first I'm JOINing tables together to know for sure that I'm not excluding any records that I wanted to include.
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Roy Chad
Milburn Brett
Dudley Goddard
Clinton Schuylerr
Dudley Goddard
Norbert Kemp
Raphael Philander
Meriwether Kennedy
Raphael Philander
Braith Cornelius
Sonnie Davin
NULL
RIGHT OUTER JOIN returns all records from RIGHT table and matches records from left table. The following two queries can be written as RIGHT or LEFT join with same results.
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
RIGHT OUTER JOIN Student s
ON s.TeacherID = t.ID
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Student s
LEFT OUTER JOIN Teacher t
ON s.TeacherID = t.ID
In this result set because we reversed the condition of LEFT JOIN above, we can see record from Student table "Dion Hayden" who is not matched with a teacher record.
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Roy Chad
Milburn Brett
Dudley Goddard
Clinton Schuylerr
Dudley Goddard
Norbert Kemp
Raphael Philander
Meriwether Kennedy
Raphael Philander
Braith Cornelius
NULL
Dion Hayden
FULL OUTER JOIN attempts to match records from both tables just like INNER JOIN and also returns all additional records that do not match from ether table.
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
FULL OUTER JOIN Student s
ON s.TeacherID = t.ID
In the this result set we have all records that we had from INNER JOIN, plus extra record from LEFT JOIN and one record from RIGHT JOIN. Teacher "Sonnie Davin" appears in result set without student and Student "Dion Hayden" also appears in result set without teach. This join is most usefull when need to get all records no matter if match exists or not.
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Roy Chad
Milburn Brett
Dudley Goddard
Clinton Schuylerr
Dudley Goddard
Norbert Kemp
Raphael Philander
Meriwether Kennedy
Raphael Philander
Braith Cornelius
Sonnie Davin
NULL
NULL
Dion Hayden
CROSS JOIN, returns all records from main table and matches them to every record from secondary table.
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
CROSS JOIN Student s
What we get back is the following result set that has every record from both table. Since no condition has be specified every record appears in result set. Number of records in result set will always be equal to Number of records in TableA multiple by number of record in TableB. In our case we had 4 Teachers and 7 Students therefore we got 28 records in result. But what if we had 4 million teachers and 70 million students. This JOIN has worst performance and will require most memory to complete the operation.
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Roy Chad
Milburn Brett
Roy Chad
Clinton Schuylerr
Roy Chad
Norbert Kemp
Roy Chad
Meriwether Kennedy
Roy Chad
Braith Cornelius
Roy Chad
Dion Hayden
Dudley Goddard
Jepson Balfour
Dudley Goddard
Milburn Brett
Dudley Goddard
Clinton Schuylerr
Dudley Goddard
Norbert Kemp
Dudley Goddard
Meriwether Kennedy
Dudley Goddard
Braith Cornelius
Dudley Goddard
Dion Hayden
Raphael Philander
Jepson Balfour
Raphael Philander
Milburn Brett
Raphael Philander
Clinton Schuylerr
Raphael Philander
Norbert Kemp
Raphael Philander
Meriwether Kennedy
Raphael Philander
Braith Cornelius
Raphael Philander
Dion Hayden
Sonnie Davin
Jepson Balfour
Sonnie Davin
Milburn Brett
Sonnie Davin
Clinton Schuylerr
Sonnie Davin
Norbert Kemp
Sonnie Davin
Meriwether Kennedy
Sonnie Davin
Braith Cornelius
Sonnie Davin
Dion Hayden
This concludes the first look at logical JOIN operations. Just like I mentioned in beginning of the post, just about every time I write query it ends up being LEFT or INNER JOIN. Do I ever had to use others? Yes, but with specific business cases.
Please leave a comment with questions and/or feedback on post.