Having already covered the basics of SQL Join syntax, now it is time to jump into a little more advanced stuff. Early in my career, I remember being confused about the difference in results when the same clause is placed in JOIN instead of WHERE clause. This post is aimed to clarify those questions and few others around ON and WHERE clauses. For demonstration I will use table built and populated in SQL Joins - Basics Part 1
First, let us look at basic LEFT join from Part 1. All rows are returned from Teacher table and all matching rows from Student table are displayed.
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
LEFT OUTER JOIN Student s
ON s.TeacherID = t.ID
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Roy Chad
Milburn Brett
Dudley Goddard
Clinton Schuylerr
Dudley Goddard
Norbert Kemp
Raphael Philander
Meriwether Kennedy
Raphael Philander
Braith Cornelius
Sonnie Davin
NULL
Now we introduce simple WHERE clause. By adding condition to WHERE clause we are now restricting entire results set to specific condition, any rows that do not satisfy that condition are excluded from results. Therefore we only end up with one row seen below.
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
LEFT OUTER JOIN Student s
ON s.TeacherID = t.ID
WHERE s.FullName = 'Jepson Balfour'
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
So what happens when you move same clause to the ON clause? Ok, lets test it!
SELECT t.FullName AS TeacherFullName
,s.FullName AS StudentFullName
FROM Teacher t
LEFT OUTER JOIN Student s
ON s.TeacherID = t.ID
and s.FullName = 'Jepson Balfour'
TeacherFullName
StudentFullName
Roy Chad
Jepson Balfour
Dudley Goddard
NULL
Raphael Philander
NULL
Sonnie Davin
NULL
What happened? Result set looks nothing like first or second example. When I first did that I was thoroughly confused. To explain the result lets run another query.
SELECT s.FullName
FROM dbo.Student as s
WHERE s.FullName = 'Jepson Balfour'
StudentFullName
Jepson Balfour
Even though last two queries look different in reality they are placing exactly same restriction on Student table. On clause on Student table became where clause that restricts results to only rows that specific that critirea. Since Teacher table is not joined with INNER join it is not restricted by what happens to Student therefore we see all Teachers displyaed but only one of them actually showing a student.
Conclusion:
The ON clause is a powerfull way to change your result set exactly to what you need it to be, but if used without understanding of what happens to the data it can produce unpredicted result set. Each statement placed in ON clause will be evaulated prior to WHERE clause. This goes back to understanding order of operations in SQL Server. Below are just few of the operations listed in correct order. By knowing and understanding the order of operations in SQL Server it helps to understand why queries behaved the way that they did above. Each one was evaluated by SQL Server in correct order which produced correct output based on that structure.
FROM
ON
WHERE
SELECT
As always feel free to leave comments, questions, etc. For next post I will answer common question of TOP clause.
Today I stumbled upon a blog post that pointed out how inefficient NOT IN clause and comment was made to use LEFT OUTER JOIN because it is "faster". They showed execution plans of both and SSMS query cost from Actual Execution plan. The first thing that jumped out at me were the Table scans that were present in both plans. Since I did some reading previously on how these suppose to yield almost similar results I decided to give this test a try myself.
To begin with, I created tables in my test database and pulled over data from AdventureWorks2014 database. To avoid extra operations that I did not want to skew results, I took the liberty of changing NVARCHAR to VARCHAR and drop extra columns that served no purpose in my tests.
--CREATE Clustered Tables
CREATE TABLE dbo.Person_Clustered
(
[BusinessEntityID] INT NOT NULL
PRIMARY KEY
, [PersonType] CHAR(2) NOT NULL
, [FirstName] VARCHAR(50) NOT NULL
, [LastName] VARCHAR(50) NOT NULL,
)
CREATE TABLE dbo.MyPeople_Clustered
(
[MyPeople_ID] INT NOT NULL
PRIMARY KEY
, [PersonType] CHAR(2) NOT NULL
, [FirstName] VARCHAR(50) NOT NULL
, [LastName] VARCHAR(50) NOT NULL,
)
--CREATE NonClustered Tables
CREATE TABLE dbo.Person_NonClustered
(
[BusinessEntityID] INT NOT NULL
, [PersonType] CHAR(2) NOT NULL
, [FirstName] VARCHAR(50) NOT NULL
, [LastName] VARCHAR(50) NOT NULL,
)
CREATE TABLE dbo.MyPeople_NonClustered
(
[MyPeople_ID] INT NOT NULL
, [PersonType] CHAR(2) NOT NULL
, [FirstName] VARCHAR(50) NOT NULL
, [LastName] VARCHAR(50) NOT NULL,
)
--Write all data from base table
INSERT INTO dbo.Person_Clustered
( BusinessEntityID
, PersonType
, FirstName
, LastName
)
SELECT BusinessEntityID
, CONVERT(CHAR(2), PersonType)
, CONVERT(VARCHAR(20), FirstName)
, LastName
FROM AdventureWorks2014.Person.Person
--Write some data to it,
INSERT INTO dbo.MyPeople_Clustered
SELECT *
FROM dbo.Person_Clustered AS p
WHERE p.BusinessEntityID % 133 = 0
INSERT INTO dbo.MyPeople_NonClustered
SELECT *
FROM dbo.MyPeople_Clustered AS p
INSERT INTO dbo.Person_NonClustered
SELECT *
FROM dbo.Person_Clustered AS p
SELECT COUNT(*) dbo.Person_Clustered
SELECT COUNT(*) dbo.Person_NonClustered
SELECT COUNT(*) dbo.MyPeople_Clustered
SELECT COUNT(*) dbo.MyPeople_NonClustered
For the actual test I created few different scenarios including NOT EXISTS and EXCEPT clauses. First 4 test are based on clustered primary keys and last 4 are based on non-clustered tables.
--Clustered Tables - NOT IN
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_Clustered AS p
WHERE p.BusinessEntityID NOT IN ( SELECT mp.MyPeople_ID
FROM dbo.MyPeople_Clustered mp )
--Clustered Tables - NOT EXISTS
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_Clustered AS p
WHERE NOT EXISTS ( SELECT 1
FROM dbo.MyPeople_Clustered mp
WHERE mp.MyPeople_ID = p.BusinessEntityID )
--Clustered Tables - LEFT OUTER JOIN
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_Clustered AS p
LEFT OUTER JOIN dbo.MyPeople_Clustered mp
ON mp.MyPeople_ID = p.BusinessEntityID
WHERE mp.MyPeople_ID IS NULL
--Clustered Tables - EXCEPT
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_Clustered AS p
EXCEPT
SELECT mp.MyPeople_ID
, mp.PersonType
, mp.FirstName
, mp.LastName
FROM dbo.MyPeople_Clustered AS mp
--NonClustered Tables - NOT IN
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_NonClustered AS p
WHERE p.BusinessEntityID NOT IN ( SELECT mp.MyPeople_ID
FROM dbo.MyPeople_NonClustered mp )
--NonClustered Tables - NOT EXISTS
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_NonClustered AS p
WHERE NOT EXISTS ( SELECT 1
FROM dbo.MyPeople_NonClustered mp
WHERE mp.MyPeople_ID = p.BusinessEntityID )
--NonClustered Tables - LEFT OUTER JOIN
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_NonClustered AS p
LEFT OUTER JOIN dbo.MyPeople_NonClustered mp
ON mp.MyPeople_ID = p.BusinessEntityID
WHERE mp.MyPeople_ID IS NULL
--NonClustered Tables - EXCEPT
SELECT p.BusinessEntityID
, p.PersonType
, p.FirstName
, p.LastName
FROM dbo.Person_NonClustered AS p
EXCEPT
SELECT mp.MyPeople_ID
, mp.PersonType
, mp.FirstName
, mp.LastName
FROM dbo.MyPeople_NonClustered AS mp
Since the point of this test was compare execution times and actual plans I captured actual execution plans using SSMS and compared run duration using SQL Sentry Plan Explorer.
Conclusion:
As it can be seen from my test, all 4 operations performed almost identical plans and almost within few milliseconds of each other. In case of Non-Clustered tables operations changed from clustered index scans to table scans but duration was still on point. In case of EXCEPT clause on Non-Clustered tables it introduced additional sort operations.
Looking at NOT IN and NOT EXISTS those operations produced identical plans and LEFT OUTER JOIN actually required one more operation to complete on top of those performed by first two.
This is exactly why I will continue to test code multiple ways and might use one way over another depending on situation.
During another day on twitter, I started friendly discussion on about which cursor options are faster versus another. Since I love a little challenge, I decided to recreate test scenario, but to be "fair" to the cursor since I have a soft spot for them since my Oracle days, I changed code just slightly by "fixing" few things that could hinder clean fight.
First thing I did was to place both cursors into stored procedures so I can easily call it, and next I modified code to write test result to a table instead of trying to calculate them by hand after each run. At the bottom of the page is the code to setup test.
I have done "cold" testing to remove extra factors that can contribute to inconclusive results. I ran each of the following query 20 times.
Query 1
DBCC FREESESSIONCACHE
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
GO
exec dbo.Cursor_KeySetTest
Query 2
DBCC FREESESSIONCACHE
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
GO
exec dbo.Cursor_FASTForward
Query 3
DBCC FREESESSIONCACHE
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
GO
SET NOCOUNT ON;
SELECT TOP 0 * INTO vSWA FROM Sales.vStoreWithAddresses
DECLARE @StartTime datetime2 = SYSDATETIME()
INSERT INTO vSWA
SELECT BusinessEntityID
, Name
, AddressType
, AddressLine1
, AddressLine2
, City
, StateProvinceName
, PostalCode
, CountryRegionName
FROM Sales.vStoreWithAddresses;
DECLARE @EndTime datetime2 = SYSDATETIME()
DECLARE @Duration INT = DATEDIFF(millisecond,@StartTime,@EndTime)
INSERT INTO TestTimes (CallType, Duration, TestTime)
VALUES ('Set Based',@Duration, SYSDATETIME())
GO
DROP TABLE vSWA;
GO
Now for the results just a simple aggregate query from the table that I created.
Test Result Query
SELECT CallType
,MIN(duration) as MinDuration
,MAX(duration) as MaxDuration
,AVG(duration) as AvgDuration
,COUNT(*) NumberOfTries
FROM dbo.TestTimes as t
GROUP BY CallType
Results
Call Type
MinDuration
MaxDuration
AvgDuration
NumberOfTries
Cursor_FASTForward
122
390
191
20
Cursor_KeySetTest
162
398
232
20
Set Based
77
275
98
20
Conclusion:
In my test which was done on my desktop with Windows 10, SQL Server 2016 Developer Edition, SET BASED approach won with average duration of 98 milliseconds. Second place goes to LOCAL FAST_FORWARD with 191 millisecond average time which is twice as slow as set based approach. Third place goes to LOCAL KEYSET cursor with average duration of 232 millisecond.
In my test scenario SET BASED still faster and will likely be faster for most scenarios, so far I have only encountered 1 scenario in my work experiences where cursor was actually faster and it had to do with TSQL based ETL loading very large tables with geospatial data. Cursors have their purpose and should be used with understanding that it can create performance issues if used incorrectly. Until I see some other information I will likely stick to using LOCAL FAST_FORWARD options which seem to provide fastest CURSOR times.
CREATE PROC [dbo].[Cursor_FASTForward]
AS
BEGIN
SET NOCOUNT ON;
SELECT TOP 0
*
INTO vSWA
FROM Sales.vStoreWithAddresses ;
DECLARE curSWA CURSOR LOCAL FAST_FORWARD FOR
SELECT BusinessEntityID
, Name
, AddressType
, AddressLine1
, AddressLine2
, City
, StateProvinceName
, PostalCode
, CountryRegionName
FROM Sales.vStoreWithAddresses ;
DECLARE @BusinessEntityID INT
, @Name Name
, @AddressType Name
, @AddressLine1 NVARCHAR(60)
, @AddressLine2 NVARCHAR(60)
, @City NVARCHAR(30)
, @StateProvinceName Name
, @PostalCode NVARCHAR(15)
, @CountryRegionName Name ;
OPEN curSWA
DECLARE @StartTime datetime2 = SYSDATETIME();
FETCH NEXT FROM curSWA INTO @BusinessEntityID, @Name, @AddressType, @AddressLine1,
@AddressLine2, @City, @StateProvinceName, @PostalCode,
@CountryRegionName ;
WHILE ( @@fetch_status <> -1 )
BEGIN
IF ( @@fetch_status <> -2 )
BEGIN
INSERT INTO vSWA
( BusinessEntityID
, Name
, AddressType
, AddressLine1
, AddressLine2
, City
, StateProvinceName
, PostalCode
, CountryRegionName
)
VALUES ( @BusinessEntityID
, @Name
, @AddressType
, @AddressLine1
, @AddressLine2
, @City
, @StateProvinceName
, @PostalCode
, @CountryRegionName
)
END
FETCH NEXT FROM curSWA INTO @BusinessEntityID, @Name, @AddressType, @AddressLine1,
@AddressLine2, @City, @StateProvinceName, @PostalCode,
@CountryRegionName ;
END
DECLARE @EndTime datetime2 = SYSDATETIME()
DECLARE @Duration INT = DATEDIFF(millisecond,@StartTime,@EndTime)
INSERT INTO dbo.TestTimes (CallType, Duration, TestTime)
VALUES (OBJECT_NAME(@@PROCID),@Duration, SYSDATETIME())
CLOSE curSWA ;
DEALLOCATE curSWA ;
DROP TABLE vSWA ;
END
GO
CREATE PROC [dbo].[Cursor_KeySetTest]
AS
BEGIN
SET NOCOUNT ON;
SELECT TOP 0
*
INTO vSWA
FROM Sales.vStoreWithAddresses ;
DECLARE curSWA CURSOR LOCAL KEYSET FOR
SELECT BusinessEntityID
, Name
, AddressType
, AddressLine1
, AddressLine2
, City
, StateProvinceName
, PostalCode
, CountryRegionName FROM Sales.vStoreWithAddresses ;
DECLARE @BusinessEntityID INT
, @Name Name
, @AddressType Name
, @AddressLine1 NVARCHAR(60)
, @AddressLine2 NVARCHAR(60)
, @City NVARCHAR(30)
, @StateProvinceName Name
, @PostalCode NVARCHAR(15)
, @CountryRegionName Name ;
OPEN curSWA
DECLARE @StartTime datetime2 = SYSDATETIME();
FETCH NEXT FROM curSWA INTO @BusinessEntityID, @Name, @AddressType, @AddressLine1,
@AddressLine2, @City, @StateProvinceName, @PostalCode,
@CountryRegionName ;
WHILE ( @@fetch_status <> -1 )
BEGIN
IF ( @@fetch_status <> -2 )
BEGIN
INSERT INTO vSWA
( BusinessEntityID
, Name
, AddressType
, AddressLine1
, AddressLine2
, City
, StateProvinceName
, PostalCode
, CountryRegionName
)
VALUES ( @BusinessEntityID
, @Name
, @AddressType
, @AddressLine1
, @AddressLine2
, @City
, @StateProvinceName
, @PostalCode
, @CountryRegionName
)
END
FETCH NEXT FROM curSWA INTO @BusinessEntityID, @Name, @AddressType, @AddressLine1,
@AddressLine2, @City, @StateProvinceName, @PostalCode,
@CountryRegionName ;
END
DECLARE @EndTime datetime2 = SYSDATETIME()
DECLARE @Duration INT = DATEDIFF(millisecond,@StartTime,@EndTime)
INSERT INTO dbo.TestTimes (CallType, Duration, TestTime)
VALUES (OBJECT_NAME(@@PROCID),@Duration, SYSDATETIME())
CLOSE curSWA ;
DEALLOCATE curSWA ;
DROP TABLE vSWA ;
END
GO
CREATE TABLE dbo.TestTimes
(
ID INT IDENTITY(1,1) PRIMARY KEY
,CallType VARCHAR(150)
,Duration INT
,TestTime DateTime2
)
GO
I don't think I have tested for every scenario possible, but it is better than only a single test. With that being said, I'm a little surprised at the result. I thought that User Defined Table Type would win in every scenario but it is clear that in some cases STRING_SPLIT() function is actually faster. Just like most other things in SQL Server the answer is: It Depends!
In the case of STRING_SPLIT() function Engineers at Microsoft did amazing job optimizing it over other custom solutions that people had to resort to in the past. Of course there are limitations with it, that need to be acknowledged and taken into consideration when designing a solution. In my opinion this could be quick go to solution that is great for initial testing but needs to be heavily tested when it comes to final solution for production environment.
Just like I mentioned in previous post, estimated row count always shows 50 rows and value returned from the function is a string and needs to be converted to target type. This did not prove to be large issue in my testing but in complex execution plans it could throw query optimizer into wrong plan when getting data from other tables which could cause major slow downs.
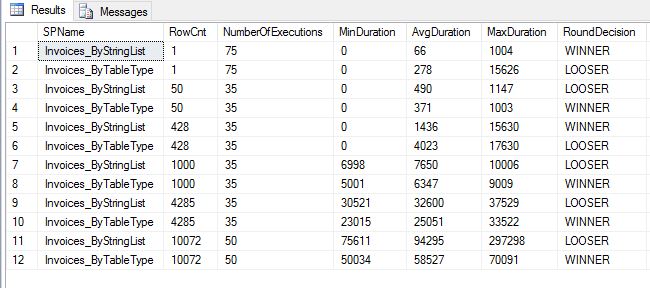
In my test scenarios outlined below, User Defined Table Type Won 4 out of 6 times. I'm sure I could have setup other scenarios where it would lose every time but in this case it won. Leave comments if you want to see full source code or want me to run any other scenarios. Thanks for reading!
SELECT a.*
, CASE WHEN ( MAX(a.AvgDuration) OVER ( PARTITION BY RowCnt ) ) = AvgDuration
THEN 'LOOSER' ELSE 'WINNER' END AS RoundDecision
, ROW_NUMBER() OVER ( ORDER BY RowCnt, SPName ) AS RowNumber
FROM (
SELECT SPName
, RowCnt
, COUNT(*) AS NumberOfExecutions
, MIN(Duration) AS MinDuration
, AVG(Duration) AS AvgDuration
, MAX(duration) AS MaxDuration
FROM dbo.SPExecutionTime
GROUP BY SPName
, RowCnt
) a
ORDER BY RowNumber
During SQL Saturday Indianapolis I heard about new function introduced in SQL Server 2016 STRING_SPLIT(). Presenter showed few examples of how to use it and mentioned that it is faster than other implementations of what people had to previously done. This got me excited and I wanted to see how it compares to User Defined Table Types which has always been my go to replacement for string splitting.
This post is not about comparing new function to other function, Aaron Bertrand already did a great post comparing it to other solutions. IT can be found here -> Performance Surprises and Assumptions : STRING_SPLIT(). What I wanted to do is compare it to User Defined Table Types because it always been faster (at least this is what I think about it).
Now unto test scenario. First time I had to replace string splitting function with User Defined Table Typed Parameter was when I had to rewrite stored procedure that accepted a list of 5000 items inside varchar(max) parameter. With that in mind I decided to test new function the same way. Pass a huge string, split it inside stored procedure and return result set back to .NET application. For this test I created two stored procedures running against Wide World Importers Test Database.
/*
==============================================================================================================================
Author: Vlady Oselsky
Create date: 08/15/2016
Description: Testing String Split Function
==============================================================================================================================
*/
CREATE PROCEDURE [dbo].[Invoices_ByTableType]
(
@List IdList READONLY
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StartTime datetime2 = SYSDATETIME();
DECLARE @RwCnt int;
select iv.SalespersonPersonID
,iv.InvoiceDate
,iv.DeliveryInstructions
from WideWorldImporters.Sales.Invoices as iv
join @List as l
on iv.InvoiceID = l.ID
order by 1
SET @RwCnt = @@ROWCOUNT
DECLARE @EndTime Datetime2 = Sysdatetime();
INSERT INTO SPExecutionTime (SPName,RowCnt, Duration)
VALUES(OBJECT_NAME(@@PROCID),@rwCnt, DATEDIFF(MICROSECOND, @StartTime, @EndTime))
END
GO
/*
==============================================================================================================================
Author: Vlady Oselsky
Create date: 08/15/2016
Description: Testing String Split Function
==============================================================================================================================
*/
CREATE PROCEDURE [dbo].[Invoices_ByStringList]
(
@List VARCHAR(MAX)
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StartTime datetime2 = SYSDATETIME();
DECLARE @RwCnt int;
select iv.SalespersonPersonID
,iv.InvoiceDate
,iv.DeliveryInstructions
from WideWorldImporters.Sales.Invoices as iv
join string_split(@List, ',') as l
on iv.InvoiceID = l.value
order by 1
SET @RwCnt = @@ROWCOUNT
DECLARE @EndTime Datetime2 = Sysdatetime();
INSERT INTO SPExecutionTime (SPName,RowCnt, Duration)
VALUES(OBJECT_NAME(@@PROCID),@rwCnt, DATEDIFF(MICROSECOND, @StartTime, @EndTime))
END
Below is the script for user defined table type and table to store results on SQL Side. I done this in order to compare SQL duration to total duration on .NET side
CREATE TYPE [dbo].[IdList] AS TABLE( [ID] [int] NULL )
GO
CREATE TABLE dbo.SPExecutionTime
(
ID INT IDENTITY(1,1) PRIMARY KEY
,SPName sysname
,RowCnt INT
,Duration INT
)
GO
Now onto .NET C# code. To be fair I wanted to pass entire value on .NET side instead of trying to build it just before calling stored procedure. Below is the code for calling TableType stored procedure, as you can see instead of having VarChar type, I have Structured type which accepts IEnumerable variable. In my case I'm passing DataTable.
stopwatch.Start(); //Time starts here
DataTable table = new DataTable();
using (var con = new SqlConnection(connectionString))
{
con.Open();
var cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "Invoices_ByTableType";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("@List", SqlDbType.Structured, -1).Value = hugeListTable;
using (var da = new SqlDataAdapter(cmd))
{
da.Fill(table);
}
}
dataGridView2.DataSource = table;
stopwatch.Stop(); //Time ends Here
Next comes a call to stored procedure with VARCHAR(MAX).
stopwatch.Start();
DataTable table = new DataTable();
using (var con = new SqlConnection(connectionString))
{
con.Open();
var cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "Invoices_ByStringList";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("@List", SqlDbType.VarChar, -1).Value = hugeListString;
using (var da = new SqlDataAdapter(cmd))
{
da.Fill(table);
}
}
dataGridView1.DataSource = table;
stopwatch.Stop();
On front end I setup simple interface with two buttons and a way to aggregate data together. After running each stored procedure 50 times. I came up with the following result.
Conclusion: Round 1 goes to User Defined Table Type. One thing I noticed when looking at execution plans. I saw that string_split() function always estimates 50 rows, whereas when calling with user defined table type estimated row count matches actual. Additionally there is implicit conversion because string returned from split function and I'm joining it to integer column. Next I want to make few other adjustment to stored procedures and front end to try to call it with different number of rows to see how it changes the outcome.
I have another opportunity to share my T-SQL knowledge. This time, it will be in Birmingham, AL at dev-data DAY on August 20. This will be a free conference with SQL, .NET, Powershell/Azure and Professional Development sessions. I'm happy to present "Crash Course on Better SQL Development" session which includes elements of T-SQL coding, error handling, a look at execution plans and finally exploring some capabilities of SSDT (SQL Server Data Tools).
This year it will by my 5th time speaking at local events. Each new event brings a new perspective into local user group communities and different knowledge that technology professionals bring to the market. For me, speaking became a way to share and at the same polish my own knowledge. Depending on experiences and knowledge of each group, there are different questions which lead a session on a slightly different path. Presenting same content takes different shape with every new group of people.
For me, one of the biggest challenges that I had to overcome in order to become a speaker was to realize that it is perfectly fine to admit that I don't know an answer to every question. Whenever a difficult question is asked, I do my best to answer based on my knowledge at that time and take a time to research it after the fact to make myself prepared for it next time. I'm not an expert in any given field and will never claim to be one. I like to be Jack of all trades. Being diverse in my knowledge helps me to approach problems from a different perspective and think of solutions from different angles.